

Understanding Scheduler Resilience
in JD Edwards
Oracle recently introduced a new feature on their JD Edwards platform called Scheduler Resilience. In this article, we’ll explore the functionality of Scheduler Resilience in JD Edwards, and how it interacts with the platform’s most popular features.
Scheduler Resilience in JD Edwards
The Scheduler Resilience feature in JD Edwards is primarily used to run notifications and orchestrations at designated intervals, which can run as a process on one or multiple AIS Servers. The Scheduler Resilience feature is able to tolerate failures, restart with little to no human intervention, and load balance if it or another scheduler is falling behind.
You may be wondering why we can’t use the standard JD Edwards scheduler to execute these sorts of jobs. The primary reason is because the standard scheduler in JDE doesn’t have a tolerance built into it. Meaning if the JDE scheduler fails, it needs human intervention to get up and running again. It also doesn’t contain any load balancing capabilities. With the Scheduler Resilience feature on the AIS Server, we can store the scheduled job properties for the notifications and orchestrations in a database. This means if a server fails, the scheduler running on the other AIS Server can continue to operate.
To explore Scheduler Resilience in JD Edwards, we’ll dive into this new feature through the following step-by-step example:

Smartbridge is an Oracle JD Edwards Gold Partner
Walking Through the Scenario
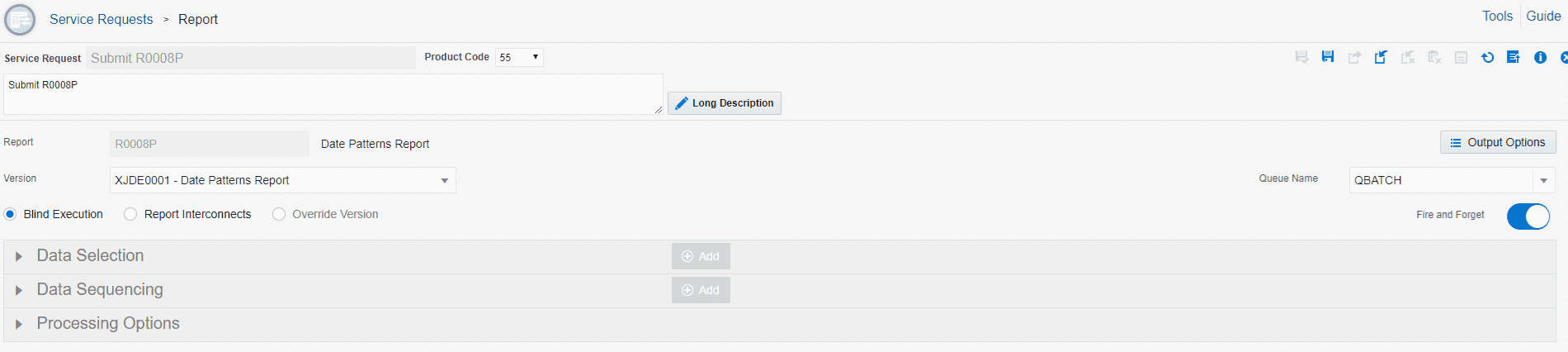
Step 1: Create an orchestration to submit a job every 5 minutes. We’ll need a service request and a schedule to create this orchestration.
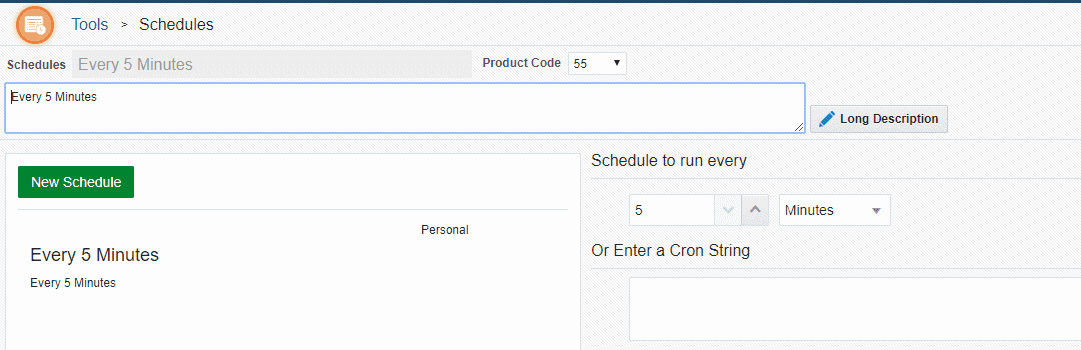
Step 2: Create a schedule.
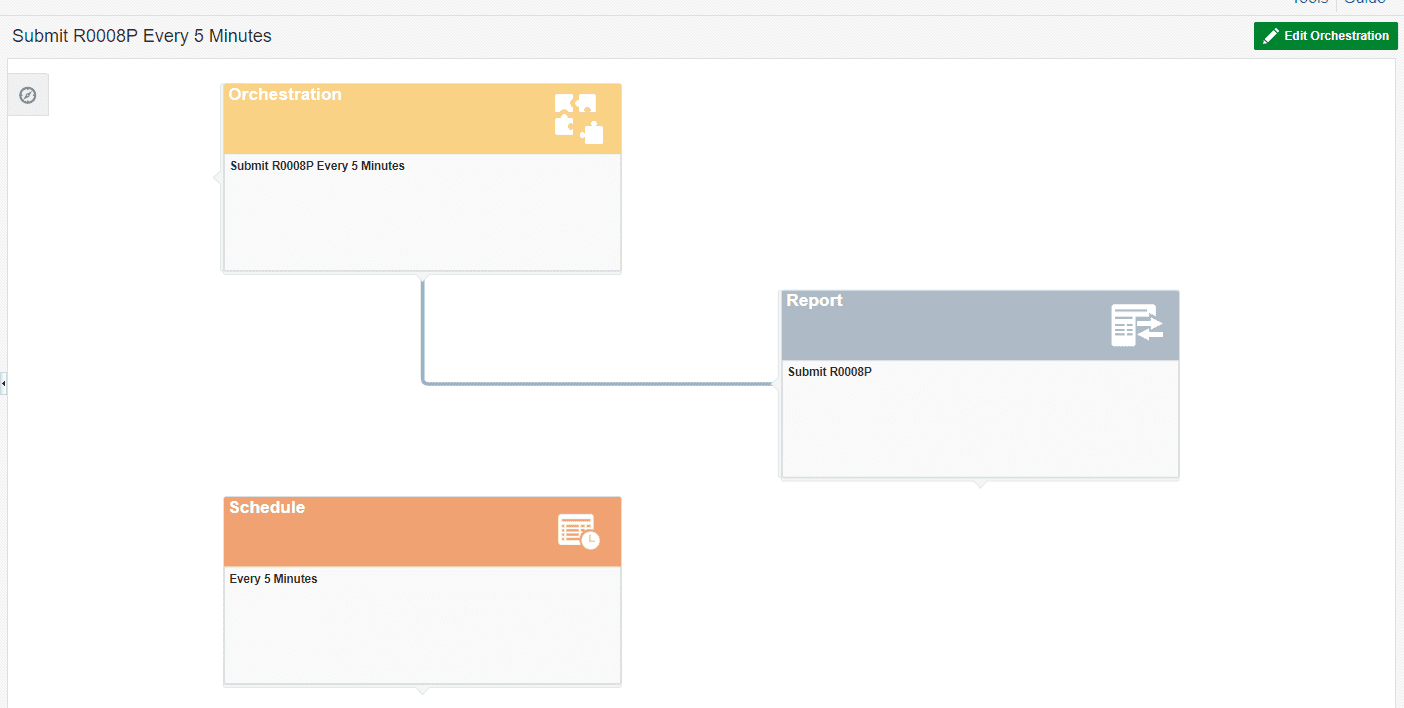
Step 3: Create an orchestration.
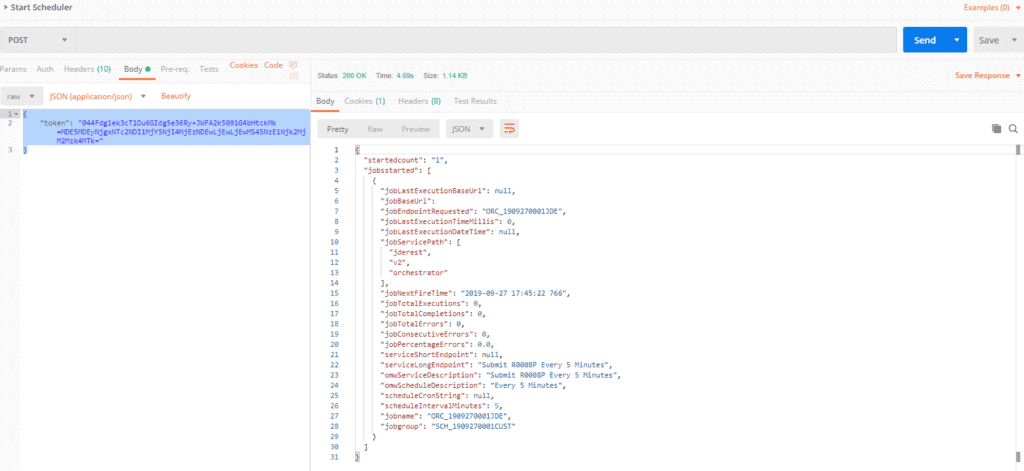
Step 4: Start the scheduler and verify the job is running successfully on the primary AIS Server (don’t forget to set necessary UDO security while doing this). In the following screenshots, you can see we’ve started the scheduler successfully.
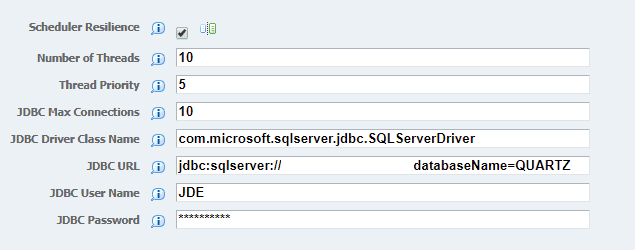
Step 5: Enable Scheduler Resilience on the AIS Server. From this point forward, the AIS scheduler will begin saving job information in the database. Keep in mind during this process, you may have to restart the AIS Server.
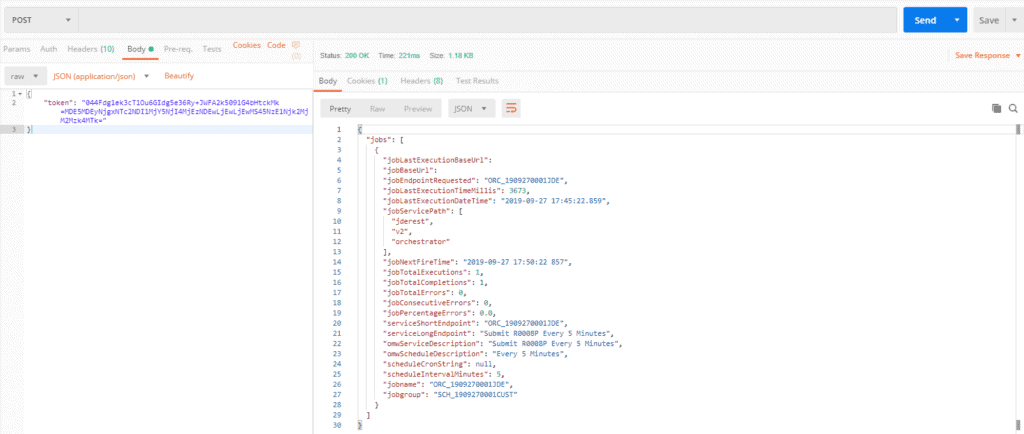
Step 6: Start the scheduler and verify that the job is getting submitted.

Concluding the Scenario
So far in this Scheduler Resilience example, we were able to accomplish the following goals:
In future blog posts, we’ll explore running the scheduler on multiple AIS Servers while simulating a full fail-over situation.
There’s more to explore at Smartbridge.com!
Sign up to be notified when we publish articles, news, videos and more!
Other ways to
follow us:
